Text Analysis on Comedy Specials:Part 1
$Comedy\ is\ subjective.$
Comedy is about delivering a story that gets a laugh. What you find funny, someone else might find it offensive or even tragic. However, what do we know about comedy?
Is there an actual formula? If so how would one explain it with emoticons?
Formula
😆 $=$ 😢 $+ \Delta t$
Where, $Comedy$, noted by 😆 is the sum an event causing great suffering relative one or a group of people, noted by 😢, and the passing of time relative to one or a group of people, noted by $\Delta t$.

ok fine!
In what it looks like a multipart tutorial, in PART 1 we will extract the transcript text for several standups that were televised over the years.
Data Extraction
To my knowledge, there is no public API for standups specials or anything related to comedy, so we need to get our data somewhere else.
While searching, I stumbled on scrapsfromtheloft.com which had quite a few transcripts from several standup specials.
We will get our data from https://scrapsfromtheloft.com/tag/stand-up-transcripts/
Understanding the structure of the page
Before we get coding, we need to find what data we need to extract and how its displayed on the page.
Under https://scrapsfromtheloft.com/tag/stand-up-transcripts/ is a list of posts with the tag stand-up-transcripts
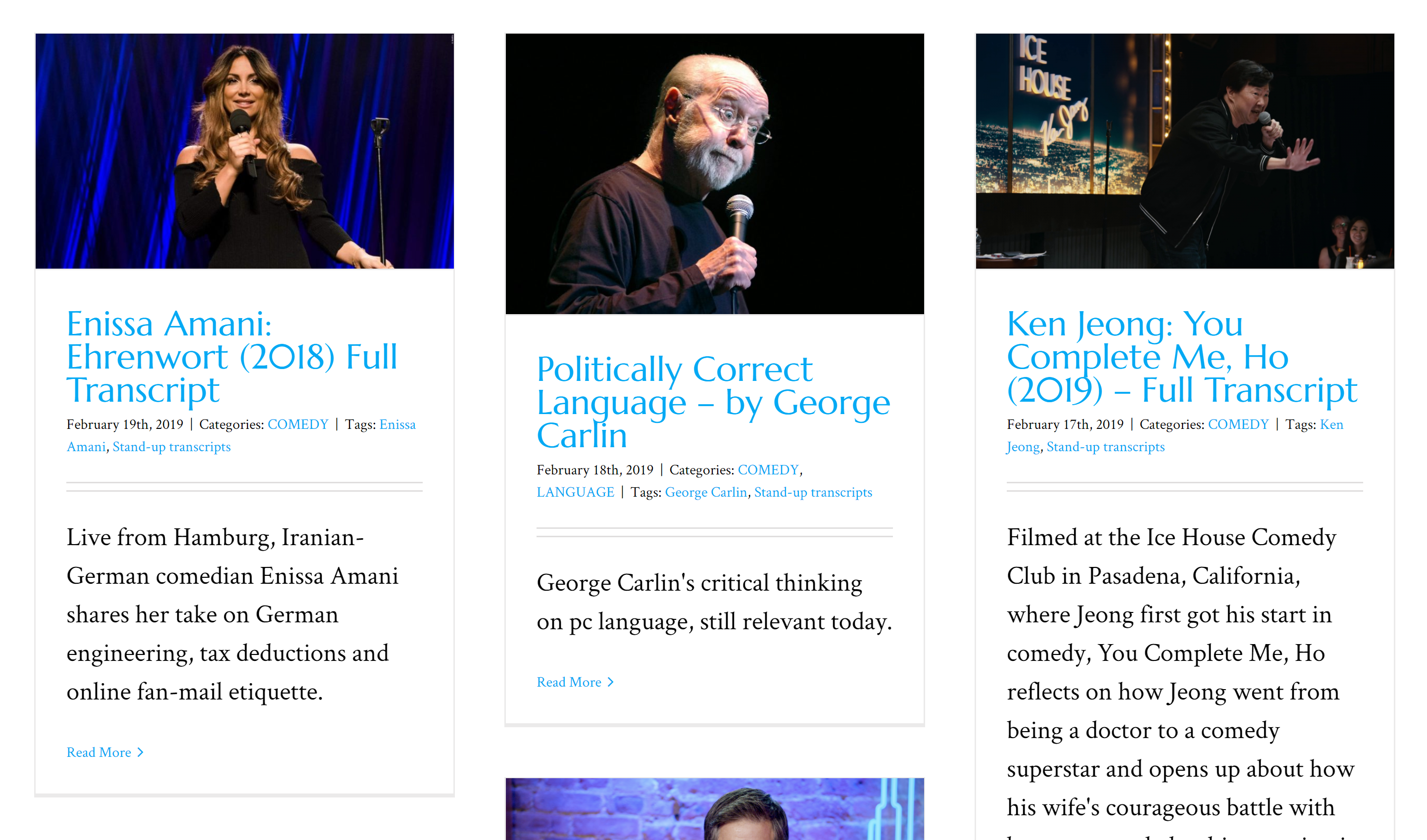
data to extract
- name of comedy special
- link to the transcript text
- name of the comedian
- summary text of the special
Under Chrome we can inspect the page with the keyboard shortcut Ctrl + Shift + I, or by right cliking and selecting “inspect”.
We can see that each post is under <div class='fusion-post-content post-content'>
- The title and transcript link are under the
<H2>and<a>tag respectively - We can extract the name of the comedian from the list of tags under
<span class='meta-tags'> - The summary text is under
<div class='fusion-post-content-container'>

Web Scraping
tools & libraries
- Python
- requests
- BeautifulSoup
- Pandas
- Jupyter Notebook
Now that we know what data to extract, we will need to find a way to download the page.
I found a great blog post on best practice on how to use requests so I will modify some of his code to fit my need.
Steps
- create a functon called
requests_retry_session()that extracts data from webpage - create a function to called
get_response()that callsrequest_retry_session()and handles errors and exceptions. - create a function called
bs_parser_post()that parses and extracts the requierd data using Beautiful soup. - create a dataframe with the extracted data
# libraries to import
import requests
import time
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
from IPython.core.display import clear_output
from warnings import warn
import os
# source: https://www.peterbe.com/plog/best-practice-with-retries-with-requests
# handles the request call
def requests_retry_session(retries=3,backoff_factor=0.3,status_forcelist=(500, 502, 504),session=None,):
''' creates request session w/several parameters returns: session '''
session = session or requests.Session()
retry = Retry(
total=retries,
read=retries,
connect=retries,
backoff_factor=backoff_factor,
status_forcelist=status_forcelist,
)
adapter = HTTPAdapter(max_retries=retry)
session.mount('http://', adapter)
session.mount('https://', adapter)
return session
# calls requests_retry_session() & handles any exceptions or errors
def get_response(url):
'''calls requests_retry_session(), handles errors returns request data'''
t0 = time.time()
try:
response = requests_retry_session().get(
url,
timeout=10
)
return response
except Exception as x:
print('It failed :(', x.__class__.__name__)
else:
print('It eventually worked', response.status_code)
finally:
t1 = time.time()
print('Took', t1 - t0, 'seconds')
def bs_parser_post(response):
''' extractd data from request call given div classes, returns 4 lists with selected data'''
titles = []
summaries = []
links = []
tags = []
page_html = BeautifulSoup(response.text, 'html.parser')
containers = page_html.find_all('div', class_ = 'fusion-post-content post-content')
for i in containers:
titles.append(i.h2.text) # title
links.append(i.a['href']) # link to transcript
tags.append(i.select('span')[6].get_text(strip=True)[5:]) # name of comedian
summaries.append(i.find('div', class_ = 'fusion-post-content-container').p.text) # summary text
return titles,summaries,tags,links
# run our code
url = 'https://scrapsfromtheloft.com/tag/stand-up-transcripts/'
response = get_response(url)
titles,summaries,tags,links = bs_parser_post(response)
df = pd.DataFrame({'raw_title': titles,
'summary': summaries,
'tags':tags,
'link': links})
# check dataframe
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 244 entries, 0 to 243
Data columns (total 4 columns):
raw_title 244 non-null object
summary 244 non-null object
tags 244 non-null object
link 244 non-null object
dtypes: object(4)
memory usage: 7.7+ KB
Results

We now have a dataframe with the data we scraped but it needs some cleaning.
We can clean up the tag column to display the name only.
df.tags = df.tags.str.replace('Stand-up transcripts','')
df.tags = df.tags.str.replace('Gun control','')
df.tags = df.tags.str.replace('SATURDAY NIGHT LIVE','')
df.tags = df.tags.str.replace('Abortion','')
df.tags = df.tags.str.replace('Religion','')
df.tags = df.tags.str.replace(',','')
# Correct name text
df.tags = df.tags.str.title()
Change the tag column name and reorder the columns
# rename column
df.rename(columns={"tags": "name"},inplace=True)
# order columns
df = df[['name','raw_title','summary','link']]
df.head()

Thats enough for today.
On the next tutorial we will extract the transcript text from each link in our dataframe.